
رگرسیون لجستیک چیست؟ (کاربردهای Logistic Regression)
۶۳۰ بازدید
0 نظر
۰۱ آبان ۱۴۰۳
آیا تا حالا برات سوال شده که چطور می شه با استفاده از داده ها، پیش بینی های دقیقی درباره آینده کرد؟ یا شاید هم کنجکاوی چطور بانک ها می تونن احتمال تقلب در تراکنش های مالی رو تشخیص بدن؟ همه این ها با یه روش قدرتمند به نام رگرسیون لجستیک انجام می شه.
رگرسیون لجستیک یکی از ابزارهای هوشمند در دنیای یادگیری ماشینه که به سازمان ها و کسب وکارها کمک می کنه تا از داده هاشون به بهترین نحو استفاده کنن. این تکنیک می تونه به شما کمک کنه تا بفهمید یه مشتری وام می گیره یا نه، یه تیم فوتبال بازی رو می بره یا نه، و حتی اینکه یه ایمیل اسپمه یا نه. در این مقاله، می خوایم با هم به دنیای جادویی رگرسیون لجستیک بریم و بفهمیم چطور این روش می تونه به بهبود تصمیم گیری ها و کارایی سازمان ها کمک کنه. آماده ای؟ پس بیایید شروع کنیم!
رگرسیون لجستیک یه الگوریتم یادگیری ماشینه که به صورت نظارت شده عمل می کنه و کارش اینه که با پیش بینی احتمال وقوع یه نتیجه یا رویداد، طبقه بندی دودویی (باینری) انجام بده. یعنی مدل دو تا خروجی ممکن داره: بله/خیر، 0/1 یا درست/نادرست.
این مدل رابطه بین یک یا چند متغیر مستقل رو تحلیل می کنه و داده ها رو به کلاس های مشخصی دسته بندی می کنه. این روش خیلی تو مدل سازی های پیش بینی استفاده می شه، جایی که مدل احتمال ریاضی اینکه یه مورد به یه دسته خاص تعلق داره یا نه رو تخمین می زنه.
برای مثال، 0 نماینده کلاس منفی و 1 نماینده کلاس مثبته. رگرسیون لجستیک بیشتر تو مشکلات طبقه بندی باینری استفاده می شه که متغیر خروجی یکی از دو دسته (0 و 1) رو نشون می ده.
چند تا مثال از این نوع طبقه بندی و جایی که پاسخ دودویی انتظار می ره یا مفهوم می شه، ایناست:
رگرسیون لجستیک یه تکنیک مهم توی زمینه هوش مصنوعی و یادگیری ماشینه. مدل های یادگیری ماشین برنامه های نرم افزاری هستن که می تونین اونا رو آموزش بدین تا کارهای پیچیده پردازش داده رو بدون دخالت انسان انجام بدن. مدل های ساخته شده با رگرسیون لجستیک به سازمان ها کمک می کنن تا از داده های تجاریشون به بینش های کاربردی برسن. این بینش ها رو می تونن برای تحلیل های پیش بینی استفاده کنن تا هزینه های عملیاتی رو کاهش بدن، کارایی رو افزایش بدن و سریع تر رشد کنن. مثلا، کسب وکارها می تونن الگوهایی رو کشف کنن که باعث افزایش نگهداری کارکنان یا طراحی محصولات پرسودتر بشن.
در ادامه، چند تا از مزایای استفاده از رگرسیون لجستیک نسبت به تکنیک های دیگه رو براتون می گم:
سادگی: مدل های رگرسیون لجستیک از لحاظ ریاضی نسبت به روش های دیگه یادگیری ماشین پیچیدگی کم تری دارن. بنابراین، حتی اگه تیم شما تخصص عمیقی توی یادگیری ماشین نداشته باشه، می تونین از این روش استفاده کنین.
سرعت: مدل های رگرسیون لجستیک می تونن حجم زیادی از داده ها رو با سرعت بالا پردازش کنن چون به توان محاسباتی کمتری مثل حافظه و قدرت پردازشی نیاز دارن. این ویژگی اونا رو برای سازمان هایی که تازه با پروژه های یادگیری ماشین شروع کردن و دنبال نتایج سریع هستن، ایده آل می کنه.
انعطاف پذیری: می تونین از رگرسیون لجستیک برای پاسخ به سوالاتی که دو یا چند نتیجه محدود دارن، استفاده کنین. همچنین می تونین ازش برای پیش پردازش داده ها استفاده کنین. مثلا، می تونین داده هایی با دامنه مقادیر زیاد، مثل تراکنش های بانکی، رو به یه دامنه محدود و کوچیکتر تبدیل کنین و بعد این داده های کوچیک تر رو با تکنیک های دیگه یادگیری ماشین برای تحلیل دقیق تر پردازش کنین.
وضوح: تحلیل رگرسیون لجستیک به توسعه دهندگان وضوح بیشتری توی فرآیندهای داخلی نرم افزار می ده نسبت به تکنیک های دیگه تحلیل داده. رفع اشکال و تصحیح خطا هم راحت تره چون محاسباتش کمتر پیچیده ست.

رگرسیون لجستیک اول به عنوان یه ابزار آماری برای تحلیل داده های پزشکی و بیولوژیکی در قرن نوزدهم ایجاد شد. اولین استفاده های ثبت شده از این تکنیک توی دهه ۱۹۴۰ توسط جوزف بریکمن و فرانک ییتس بود که برای تحلیل داده های دوتایی (دو حالته) استفاده می شد. بعدها، این روش به حوزه های مختلفی از جمله اقتصاد، مهندسی و علوم اجتماعی گسترش پیدا کرد.
با پیشرفت علم کامپیوتر و افزایش دسترسی به داده های بزرگ، رگرسیون لجستیک به یکی از ابزارهای مهم در تحلیل داده ها و یادگیری ماشین تبدیل شد. امروزه، این تکنیک در بسیاری از الگوریتم های پیش بینی و طبقه بندی استفاده می شه و نقش مهمی در تصمیم گیری های مبتنی بر داده داره.
رگرسیون لجستیک یکی از ابزارهای بسیار قدرتمند در دنیای هوش مصنوعی و یادگیری ماشینه که کاربردهای زیادی توی صنایع مختلف داره. حالا بیایید ببینیم این مدل چطور می تونه به بهبود کارایی و عملکرد سازمان ها کمک کنه.
شرکت های تولیدی از رگرسیون لجستیک برای پیش بینی احتمال خرابی قطعات ماشین آلات استفاده می کنن. این پیش بینی ها کمک می کنه تا برنامه های تعمیر و نگهداری به موقع انجام بشه و از خرابی های غیرمنتظره جلوگیری بشه، که در نهایت منجر به کاهش هزینه ها و افزایش بهره وری می شه.
در حوزه پزشکی، از رگرسیون لجستیک برای پیش بینی احتمال بروز بیماری ها استفاده می شه. پزشکان می تونن با استفاده از این مدل ها رابطه بین متغیرهایی مثل سابقه خانوادگی، وزن و سطح فعالیت بدنی رو با بیماری های مختلف تحلیل کنن و برنامه های پیشگیرانه و درمانی مناسبی تدوین کنن.
شرکت های مالی از رگرسیون لجستیک برای شناسایی تقلب در تراکنش ها و ارزیابی ریسک های مربوط به وام ها و بیمه ها استفاده می کنن. این مدل ها می تونن احتمال وقوع تقلب یا ریسک بالا رو پیش بینی کنن، که به بانک ها و شرکت های بیمه کمک می کنه تا تصمیمات بهتری بگیرن و مشتریانشون رو بهتر حفاظت کنن.
ابزارهای تبلیغات آنلاین از رگرسیون لجستیک برای پیش بینی کلیک کاربران روی تبلیغات استفاده می کنن. با تحلیل داده های کاربران و استفاده از این مدل ها، بازاریابان می تونن تبلیغات مؤثرتری ایجاد کنن که جذابیت بیشتری برای کاربران داشته باشه و منجر به تعامل بیشتر بشه.
مدل های رگرسیون لجستیک به تیم ها کمک می کنن تا ناهنجاری های داده که نشان دهنده تقلب هستن رو شناسایی کنن. رفتارها یا ویژگی های خاصی ممکنه بیشتر با فعالیت های تقلبی مرتبط باشن و این مدل ها به بانک ها و مؤسسات مالی کمک می کنن تا مشتریانشون رو از این فعالیت های مخرب محافظت کنن. همچنین شرکت های ارائه دهنده نرم افزارهای مبتنی بر سرویس از این مدل ها برای حذف حساب های کاربری تقلبی از دیتاست هاشون استفاده می کنن.
مدل های رگرسیون لجستیک می تونن به تیم های منابع انسانی و مدیریت کمک کنن تا بفهمن کدام کارکنان در خطر ترک سازمان هستن. این اطلاعات می تونه به شناسایی مشکلات داخلی سازمان مثل فرهنگ سازمانی یا سیستم های جبران خدمات کمک کنه. همین طور تیم های فروش می تونن از این مدل ها برای شناسایی مشتریانی که ممکنه به سمت رقبا برن، استفاده کنن و استراتژی های نگهداشت مناسبی تدوین کنن.
همون طور که دیدی رگرسیون لجستیک یه ابزار کاربردیه که می تونه در صنایع مختلف به کار گرفته بشه و به بهبود عملکرد و کارایی سازمان ها کمک کنه. از تولید و بهداشت و درمان گرفته تا مالی و بازاریابی، این تکنیک تحلیلی می تونه بینش های ارزشمندی ارائه بده که منجر به تصمیم گیری های بهتر و کاهش ریسک ها بشه. اگه تا حالا از این ابزار استفاده نکردی، وقتشه که دست به کار بشی و این تکنیک رو توی پروژه های خودت پیاده سازی کنی.
رگرسیون لجستیک توی دنیای یادگیری ماشین مزایای زیادی داره که باعث می شه به یه ابزار کارآمد تبدیل بشه. بیایید چند تا از این مزایا رو با هم بررسی کنیم.
راه اندازی یه مدل یادگیری ماشین با استفاده از آموزش و تست خیلی آسونه. آموزش مدل به این صورت انجام می شه که الگوهای موجود در داده های ورودی (مثلاً تصاویر) رو شناسایی می کنه و اونا رو به خروجی خاصی (برچسب) مرتبط می کنه. آموزش یه مدل لجستیک با الگوریتم رگرسیون نیاز به قدرت محاسباتی بالایی نداره. به همین خاطر، رگرسیون لجستیک نسبت به روش های دیگه یادگیری ماشین، راحت تر پیاده سازی، تفسیر و آموزش داده می شه.
داده های خطی جداپذیر به مجموعه داده هایی گفته می شه که توی نمودار با یه خط صاف می شه دو کلاس داده رو از هم جدا کرد. توی رگرسیون لجستیک، متغیر y فقط دو مقدار داره. بنابراین، اگه داده ها به صورت خطی جداپذیر باشن، می تونیم اونا رو به دو کلاس جداگانه طبقه بندی کنیم.
رگرسیون لجستیک اندازه و اهمیت متغیرهای مستقل (یا پیش بینی کننده) رو اندازه گیری می کنه و همچنین جهت رابطه یا ارتباط اونا (مثبت یا منفی) رو نشون می ده. این اطلاعات به ما کمک می کنه تا بفهمیم کدوم متغیرها تأثیر بیشتری دارن و چطور بر نتیجه نهایی اثر می ذارن.
این مزایا رگرسیون لجستیک رو به یکی از ابزارهای مورد علاقه توی یادگیری ماشین تبدیل کرده که می تونه در پروژه های مختلف مورد استفاده قرار بگیره و نتایج موثری ارائه بده.
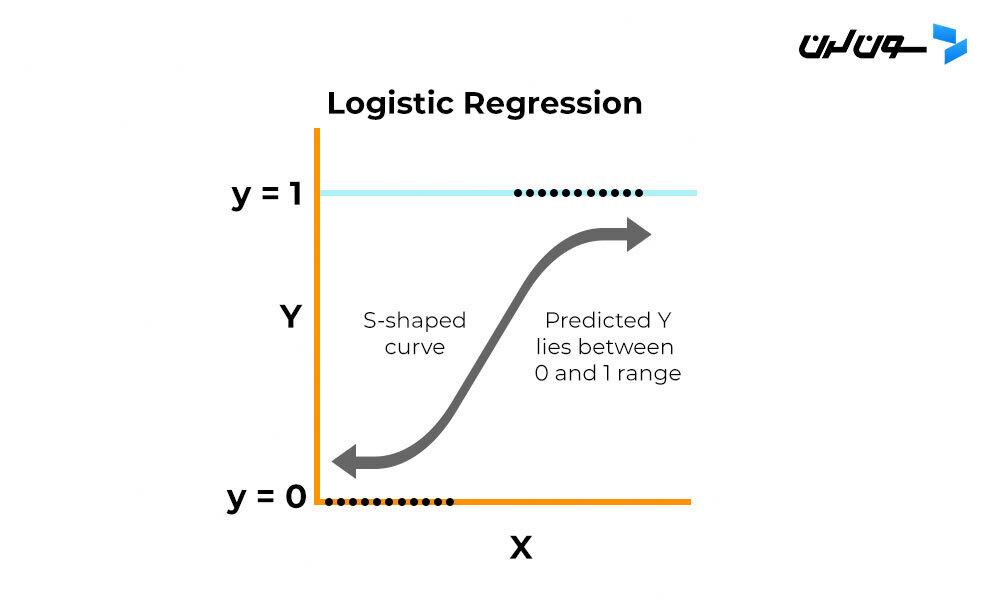
رگرسیون لجستیک از یه تابع لجستیک به نام تابع سیگموید استفاده می کنه تا پیش بینی ها و احتمالاتشون رو نشون بده. تابع سیگموید یه منحنی به شکل S هست که هر مقدار واقعی رو به بازه بین 0 و 1 تبدیل می کنه.
وقتی خروجی تابع سیگموید (احتمال تخمینی) از یه مقدار آستانه مشخص بیشتر باشه، مدل پیش بینی می کنه که مورد متعلق به اون کلاس هست. اگه این احتمال کمتر از اون آستانه باشه، مدل پیش بینی می کنه که مورد به اون کلاس تعلق نداره.
مثلاً، اگه خروجی تابع سیگموید بالای 0.5 باشه، خروجی به عنوان 1 در نظر گرفته می شه. در غیر این صورت، خروجی به عنوان 0 طبقه بندی می شه. مثلاً اگه خروجی تابع سیگموید 0.65 باشه، یعنی احتمال وقوع رویداد 65 درصد هست؛ مثل پرتاب یه سکه که احتمال شیر اومدنش 65 درصده.
تابع سیگموید به عنوان یه تابع فعال سازی در رگرسیون لجستیک شناخته می شه و به صورت زیر تعریف می شه:
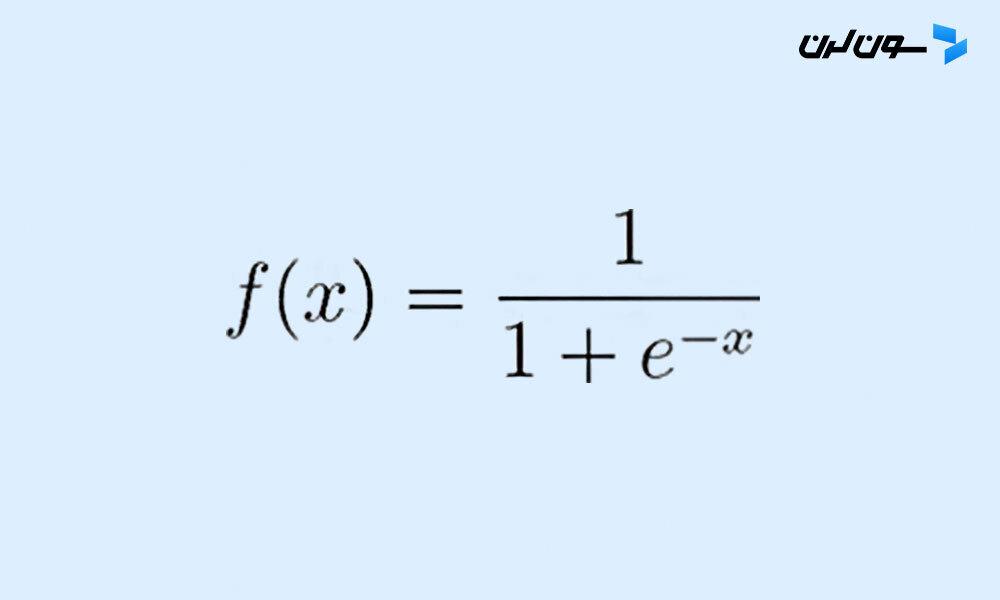
که توش:
معادله رگرسیون لجستیک به صورت زیره:
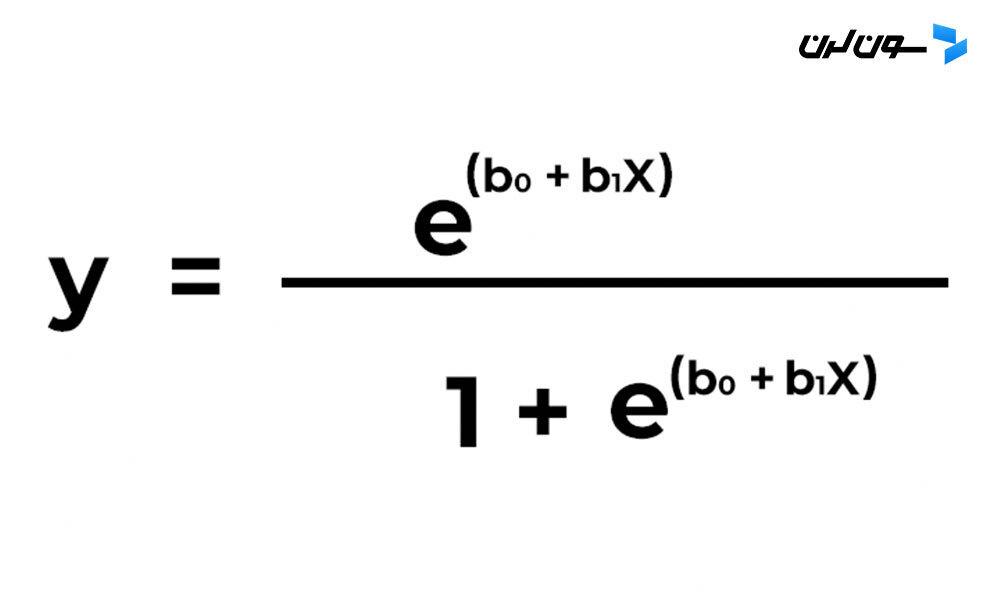
که توش:
این معادله شبیه رگرسیون خطیه که مقادیر ورودی رو به صورت خطی ترکیب می کنه تا یه مقدار خروجی پیش بینی کنه، با این تفاوت که تو رگرسیون لجستیک خروجی یه مقدار دودویی (0 یا 1) هست.
ویژگی های معمول معادله رگرسیون لجستیک شامل موارد زیره:
وقتی می خوایم رگرسیون لجستیک رو پیاده سازی کنیم، باید به چند تا فرضیه مهم توجه کنیم:
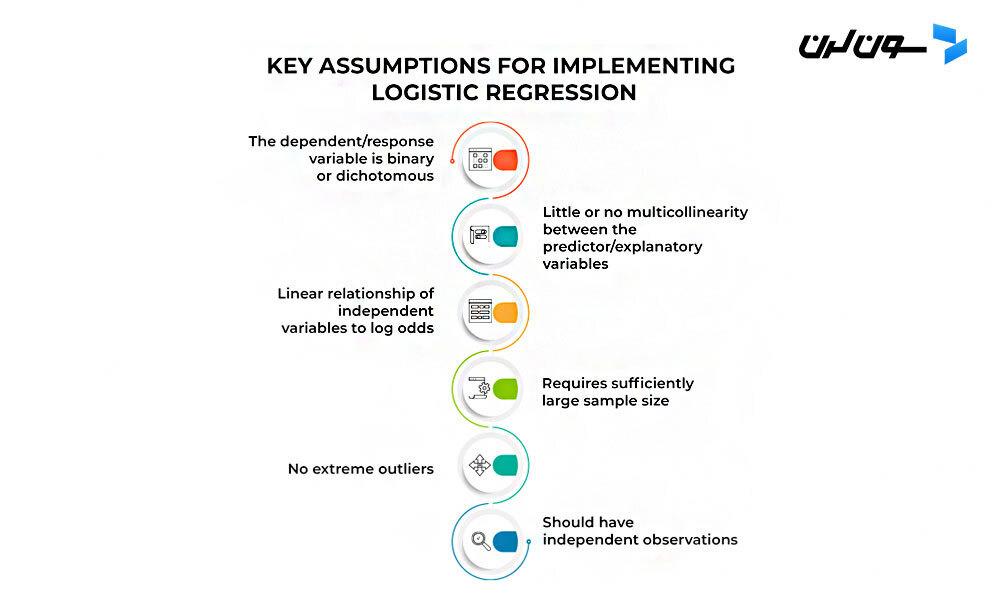
با رعایت این فرضیات، می تونیم مطمئن باشیم که نتایج مدل رگرسیون لجستیکمون معتبر و قابل اتکاست.
رگرسیون لجستیک به سه نوع اصلی تقسیم می شه: باینری، چندجمله ای و ترتیبی. هر کدوم از این انواع تو اجرا و تئوری با هم فرق دارن. بیایید هر کدوم رو با جزئیات بیشتری بررسی کنیم.
رگرسیون لجستیک باینری رابطه بین متغیرهای مستقل و یه متغیر وابسته دودویی رو پیش بینی می کنه. خروجی این نوع رگرسیون می تونه موفقیت/شکست، 0/1 یا درست/نادرست باشه.
مثال ها:
رگرسیون لجستیک چندجمله ای وقتی استفاده می شه که متغیر وابسته دسته بندی شده بیش از دو خروجی مجزا داشته باشه. این نوع رگرسیون بیشتر از دو نتیجه ممکن داره.
مثال ها:
رگرسیون لجستیک ترتیبی وقتی کاربرد داره که متغیر وابسته در یه حالت مرتب شده (ترتیبی) باشه. متغیر وابسته (y) یه ترتیب با دو یا چند دسته یا سطح رو مشخص می کنه.
مثال ها:
این سه نوع رگرسیون لجستیک هر کدوم در شرایط خاصی استفاده می شن و می تونن به ما کمک کنن تا اطلاعات دقیق تری از داده هامون به دست بیاریم و تصمیم گیری های بهتری انجام بدیم.

رگرسیون لجستیک یه روش آماری برای مدل سازی رابطه بین یه متغیر وابسته دوتایی و یک یا چند متغیر مستقل هست.
زمانی که می خواهیم احتمال وقوع یه رویداد باینری (مثلاً خرید یا عدم خرید، بیمار بودن یا نبودن) رو پیش بینی کنیم.
رگرسیون خطی برای پیش بینی متغیرهای پیوسته استفاده می شه، در حالی که رگرسیون لجستیک برای پیش بینی متغیرهای باینری کاربرد داره.
بله، رگرسیون لجستیک برای داده های باینری مناسبه. برای داده های چندکلاسه می شه از تکنیک های دیگه مثل رگرسیون لجستیک چندکلاسه استفاده کرد.
می تونی با استفاده از تکنیک های پیش پردازش داده، انتخاب ویژگی های مناسب و تنظیم هایپرپارامترها مدل خودت رو بهبود بدی.
همون طور که گفتیم رگرسیون لجستیک یکی از ابزارهای قدرتمند در تحلیل داده ها و پیش بینی رویدادهای باینری هست. با استفاده از این تکنیک می تونیم تصمیمات دقیق تری بگیریم و در حوزه های مختلف از جمله پزشکی، مالی و بازاریابی از آن بهره مند بشیم. امیدوارم که این مقاله برات مفید بوده باشه و بتونی از اطلاعاتش در پروژه های خودت استفاده کنی.







